Labeled PSI from Homomorphic Encryption with Reduced Computation and Communication
以减少计算和通信的方式从同态加密中获得标记的 PSI
众所周知,完全同态加密(FHE)可用于在不平衡设置中建立高效的(标记的)隐私集合求交协议,其中一个集比另一个大得多(Chen 等人(CCS'17,CCS'18))。在本文中,我们展示了对这些工作的多种算法改进。特别是,我们的协议有一个渐进的更好的计算成本,只需要
我们证明我们的协议在许多实际参数上明显优于 Chen 等人(CCS'18)的协议,特别是在在线通信成本方面。例如,当相交于
最后,我们展示了一种修改,在更大的集合规模
1 介绍
考虑到两方,每一方都有一个隐私的项目数据集。他们想在不向对方泄露任何其他信息的情况下了解各自数据集的交集。例如,两个国家希望通过在其警察数据库中找到匹配的身份来追踪犯罪嫌疑人,同时向对方隐藏其他敏感数据,或者两家银行希望识别有不明显的金融交易的客户,而不透露关于客户的任何其他数据。
为了解决上述问题,双方可以进行隐私集合求交(PSI)协议。PSI 指的是一种交互式加密协议,它将两个隐私集合作为输入,找到它们的交集,并将其输出给参与者中的一方或双方。如果一方获得 PSI 协议的结果(单向 PSI),我们称这一方为接收方,另一方为发送方。一般的双向 PSI 可以通过两轮单向 PSI 来实现,其中参与者互换接收方和发送方的角色。在实践中,单向 PSI 在各种隐私保护协议中作为一个重要的基本要素而存在,包括移动信使(如 Signal 或 WhatsApp)中的隐私联系人发现 [28, 42],检查漏洞数据库中是否存在泄露的密码 [2, 37],以及用于控制传染病传播的联系人追踪 [60]。
在这项工作中,我们专注于单向 PSI 的一个变体,其中接收方的集合比发送方的小得多。我们还假设接收方的计算和存储资源有限(例如,手机或可穿戴设备),而发送方配备了更强大的机器(例如,数据中心的服务器)。这种特定的设置被称为不平衡的。因此,不平衡的设置的目标是将尽可能多的计算委托给发送方,并减少双方的通信。
令
按照 [13] 的大纲,我们还考虑了标签化的 PSI,这是一种特殊类型的带计算的 PSI。在这种情况下,发送方集合中的每个元素都有相关的数据标签,而接收方希望了解交集中的元素的标签。这是由 Chor 等人 [16] 介绍的单服务器隐私信息检索(PIR)问题的一般化。标签化 PSI 的实际应用包括有针对性的价格歧视 [45] 和移动信使中的密钥检索 [28, 42],其中用户查询其联系人列表中的人的公钥。
1.1 相关工作
20 世纪 80 年代的早期 PSI 协议 [33,43] 是基于 DiffieHellman(DH)密钥交换的 [18]。从本质上讲,Alice 和 Bob 对他们集合中的每一个元素进行 DH 密钥交换;如果产生的共享秘密相匹配,就会发现匹配。Freedman 等人 [24] 介绍了一个基于不经意多项式评估和同态加密的协议。Ateniese 等人 [4] 介绍了一种基于 RSA 累加器的结构。由于 PSI 可以被认为是安全两方计算的一个特例,因此可以使用标准技术,如混淆电路来构建 PSI 协议 [32, 49, 51]。最近,许多协议 [12, 19, 40, 46, 48, 52, 55] 都是基于 OT 扩展 [34] 和不经意伪随机函数(OPRF)。
上述工作主要是为平衡设置而设计的,其中发送方集与接收方集大致相同。下面我们将放大文献中的两个最有效的非平衡设置的范式,这也是本工作的重点。
1.1.1 基于 OPRF 的不平衡 PSI
一个基于 OPRF 的 PSI 协议首次在 [23] 中提出,其中 OPRF 是由 Naor-Reingold(NR)伪随机函数 [44] 构建的。在混淆电路(GC)[61] 的帮助下,后来的工作从基于 AES 的 OPRF [50] 引入了一个 PSI 协议。目前最先进的协议在 Kales 等人 [36] 的工作中实现,它来自 [39] 和 [54]。该协议有两个阶段,预处理阶段和在线阶段。作者引入了许多优化,将尽可能多的计算和通信成本推到预处理阶段。下面我们对这一思路的协议思想进行概述。在预处理阶段,具有大集合
在线阶段是非常有效的,并且不依赖于发送方的集合大小。对于一个有
1.1.2 基于 FHE 的不平衡 PSI
在光谱的另一边,Chen 等人 [14] 引入了一个基于
在这两项工作 [13, 14] 中,都使用了 BFV 方案 [22],它有
该工作原理是这项工作的起点。因此,我们将详细解释推迟到第三节。
1.2 贡献
我们对 Chen 等人 [13, 14] 的协议进行了一些优化和改进,从而改善了运行时间,并提高了发送方集合大小的通信复杂性。我们的贡献可以总结为以下几点。
- 我们展示了如何去除 [13] 中使用的缓慢的扩展场算术,同时仍然支持任意长度的项目和标签。
- 我们通过使用极端邮票基数 [11] 而不是 [13, 14] 中效率较低的窗口技术来降低通信成本。
- 我们展示了如何使用 Paterson-Stockmeyer 算法 [47] 在
密文间乘法中评估交叉电路,这比 [13] 有了四倍的改进。 - 我们使用 [56] 的技术来实现 FourQ 曲线 [17] 的一个非常快速的哈希曲线的实现。基于 OMGDH 的 OPRF 协议 [13, 35, 54] 需要哈希到曲线,这是我们协议的一个关键组成部分。
- S 我们通过利用无深度的同态 Frobenius 自动化来改善通信开销。这种操作允许计算
,其中 是 FHE 方案的明文模数,而不需要密文间乘法。因此,为了计算深度为 的交叉电路,发送方只需要 个密文。这将通信复杂度从先前工作 [13, 14] 中给出的 降低到了 ,其中 。 - 我们创建了一个我们协议的开源参考实现。
2 初步了解
2.1 符号
在本文中,我们用
2.2 不平衡的 PSI
有接收方和发送方,两方分别拥有一个集合
2.3 全同态加密
全同态加密(FHE)是一个加密方案系列,允许在不解密的情况下对加密数据进行任意操作。大多数现有的 FHE 方案 [69, 15, 20, 22, 25, 27] 是基于 LWE [53] 或 RLWE [41] 问题,这意味着加密信息中存在噪音。与密码文本相关的噪声随着每次同态操作的进行而增长(加法是加法增长,乘法是乘法增长)。因此,为了避免解密错误,我们必须注意确保噪音不会大到足以干扰基础明文。这种噪音管理是通过两个框架实现的。
第一个框架包括一个有限同态加密(somewhat homomorphic encryption, SHE)方案,它能够同态计算自己的解密电路,或者执行一个所谓的引导操作,减少噪音大小。对于这样的 FHE 方案,加密参数可以被固定,以便在给定引导信息的情况下,任何电路都可以计算。然而,与其他同态操作相比,引导操作要慢得多;因此,在实践中通常会避免这种操作。
第二个框架的想法是选择足够大的加密参数来计算一个预先确定的电路系列。在这种情况下,从来没有使用引导,但加密参数随着电路的深度而增长。其加密参数随着电路深度的增加而呈多项式增长的 SHE 方案被称为
在这项工作中,我们使用了两个
这些方案的明文空间被类比定义为
噪声大小由噪声分布的标准偏差
参数
同态操作及其成本:我们使用的基本同态运算是加法和乘法,它们可以在两个密文或由密文和明文组成的组元上进行。我们还将使用 Frobenius 运算,给定一个加密信息
每个同态操作的成本由其运行时间和添加到其输出的噪声量定义。对于成本分析,我们假设密文和明文都以 Double-CRT 形式表示 [26],密文的噪声以其无穷大规范来衡量。我们还假设使用混合密钥切换方法(更多细节见 [38])。
同态加法是最后一个昂贵的操作,只需要
明文与密文的乘法,我们称之为标量乘法,相当于
密文与密文的非标量乘法有两个步骤:向量卷积和密钥切换。第一步执行
Frobenius 操作首先对密码文本的 Double-CRT 形式进行置换,然后进行密钥切换。置换不需要整数乘法。因此,Frobenius 操作比非标量乘法更快,其运行时间被密钥切换所支配;它需要
总而言之,无论是在运行时间还是在噪声增长方面,最昂贵的同态操作都是非标量乘法。因此,我们用非标量乘法的数量来衡量我们算法的运行时间复杂性。我们还衡量了我们的电路与非标量乘法有关的深度。那么,我们说,一个(顺序的)非标量乘法会消耗一个乘法层次。
请注意,在计算密文的平方时,非标量乘法有时可以用 Frobenius 运算代替。由于 Frobenius 运算只引入了加性噪声,我们说 Frobenius 运算不消耗任何乘法等级,也就是说,它是无深度的。
3 不带标签的 PSI
我们的基本 PSI 协议严格遵循 Chen 等人 [13, 14] 的框架,这些框架是基于 [49] 的想法。
输入: 接收者有一个大小为
输出: 接收者输出
设置: 接收方和发送方商定一个 SHE 方案,明文空间是一个有限域
接收方生成 SHE 方案的公钥和私钥。发送方对
我们注意到,使用
接下来,接收方将每个
交集: 给出仓
安全性: 如 [13] 所示,
3.1 优化
在这一节中,我们讨论了各种优化技术,以使上述协议实用。其中一些(SIMD 打包、分割和分窗)在过去的 [13, 14] 中已经讨论过了,并且对我们的协议仍然至关重要。我们改进了 SIMD 打包技术,只使用更有效和更灵活的素数域,尽管这主要是在下面第 4 节讨论的标记情况下提出的挑战。我们利用 Paterson-Stockmeyer 算法 [47] 来提高计算复杂性,并实现新的通信 - 计算权衡。我们改变了开窗技术,使用更有效的极端邮票基数 [10, 11],这在许多情况下大大降低了我们的通信成本。我们展示了可以用零乘法深度计算接收器输入的多少个幂,从而产生了一个通信成本极低的协议变体。最后,我们为 FourQ 椭圆曲线 [17] 改编了 Elligator 2 [5] 图,以实现快速哈希到曲线,这是基于
基于交换的散列 [49] 可以在我们的工作中立即应用,以减少项目长度的几个比特。但是,与我们的其他技术相比,这种技术对性能的影响微乎其微,所以我们没有把它纳入这项工作。
3.1.1 SIMD 打包
正如第 2.3 节所讨论的,我们可以将多个数据值打包到一个密文中,这样这些值就可以同时被同态操作处理。使用这种方法,接收方基本上可以把密文中的槽当作布谷鸟哈希表
在 [13] 中,作者能够支持任意长度的项目,首先将它们散列到一个较小的域中,并使用 SIMD 打包,扩展字段的值大到足以容纳哈希值。不幸的是,扩展字段运算会对性能产生破坏性的影响;这种影响在标签模式下尤为突出。此外,扩展字段必须具有一定的大小特征才能发挥作用,这在某些情况下会导致次优的参数选择。
我们观察到,完全不使用扩展字段是可能的,而只在素数域上使用 SIMD 打包。由于元素哈希值大于一个 SIMD 槽,我们简单地将哈希值拆分,以占据几个连续的槽。这在 [13] 中是不可能的,因为作者认为
3.1.2 分割
为了减少计算深度,[14] 提出将每个发送者的仓分成
为了计算度数为
3.1.3 Paterson-Stockmeyer 算法
分区的一个问题是,在许多情况下,把
首先,挑选正整数
事实上,Paterson 和 Stockmeyer 设计了一个稍快的算法,具有相同的渐近复杂度。不幸的是,在我们的工作中不能直接利用它,因为它依赖于这样一个事实:被评估的多项式的系数环是一个欧几里得域。
如果使用分区技术,那么
例 1. 考虑一个大小为
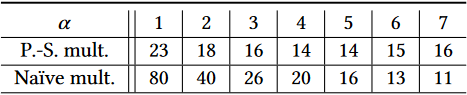
在附录 A 中,我们展示了如何从
3.1.4 分窗
在现代的
Paterson-Stockmeyer 算法的乘法深度(如公式(2))等于
在实践中,固定一个乘法深度
让
按照上面的讨论。我们得到,接收方应发送
定理 2:要用 Paterson-Stockmeyer 方法计算一个度数为
证明可以在附录 B 中找到。
3.1.5 极值邮票基 (Extremal postage-stamp bases)
上面描述的 [14] 的窗口技术很容易使用:接收器总是确切地知道要发送哪些幂。不幸的是,它远非最优。为了证明这一点,考虑一个
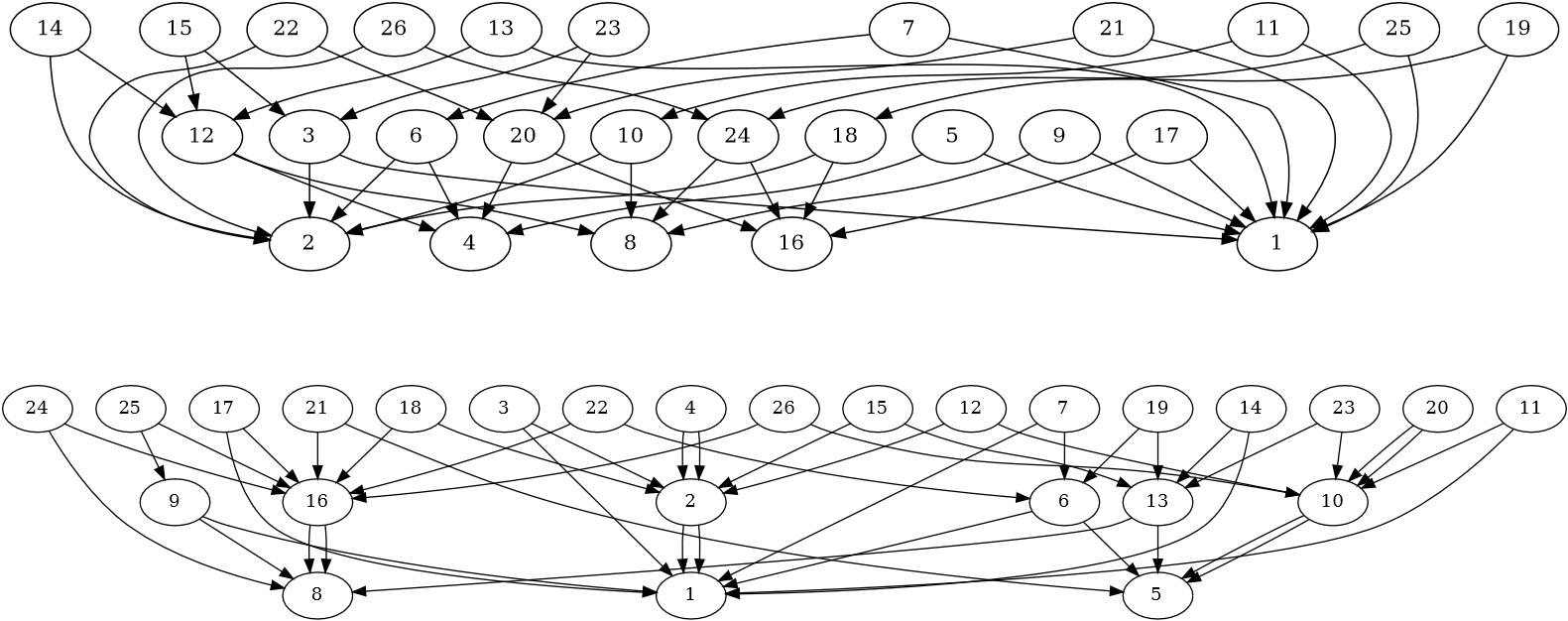
图 1:图中描述了发送方从一组给定的源幂中计算出接收方查询的所有幂至 26 的两种可能方式。从一个节点上伸出的两个箭头表示哪些较低的幂需要相乘,以产生节点标签中所示的幂。
更一般地说,我们想回答的问题是:应该发送哪些查询的幂,以便发送者能够计算查询的所有幂,直到尽可能大的边界
这个问题可以被看作是全球邮戳问题的一个变种 [10, 11]。
定义 3(全球邮票问题):给定正整数
与我们的问题的联系是明确的。在定义 3 的符号中,如果接收方将加密的幂
目前还不知道寻找极值邮票基的简单方法,也不知道全局邮票问题的复杂度等级。此外,极值解往往是唯一的(或几乎是唯一的),并很快变得难以找到。幸运的是,我们只需要该问题的小实例的解决方案,这些解决方案已经被破解,并在 [11] 中提出。
极值邮票基可以通过两种方式用于 Paterson-Stockmeyer 算法。回顾一下,在这种情况下,发送方必须计算接收方查询的所有幂,直到某个正整数
当然,可以使用
例如,再次考虑图 1 中的极值邮票基
具有大
3.1.6 通过 Frobenius 操作实现低深度指数化
如第 2.3 节所述,从运行时间和增加的噪声来看,Frobenius 运算是一种更便宜的非标量乘法的替代方法。使用这种操作,发送方可以计算
例 4:取一个明文模数
假设发送方在其集合中有
然而,发送方可以通过应用 Frobenius 运算
在增加深度的代价下,通信复杂度可以进一步降低。如果接收方只发送
上面的想法在定理 5 中得到了正式体现,该定理指出了发送方用深度为
定理 5:令
例 6:令
例 7:令
这种技术要求接收方发送额外的评估密钥来进行 Frobenius 操作。特别是,接收方应该向发送方发送
在实践中,Frobenius 操作的优势与 SIMD 打包能力相矛盾。一般来说,打包能力等于
3.1.7 来自 FourQ 的快速 OPRF
正如第 3.1.1 节所指出的,
出于性能方面的考虑,我们使用 FourQ 曲线 [17] 作为群,它提供了随机点的快速标量乘法,以及如下的哈希到曲线的快速实现。我们应用二元映射
我们测量了我们的实现,从哈希到曲线的函数需要大约 12000 个时钟周期,标量乘法需要 42000 个时钟周期。这比 Aranha 和 Resende [54] 为不平衡 PSI 应用优化的曲线 GLS-254 快,后者的标量乘法需要大约 50,000 个时钟周期。
4 标签化 PSI
4.1 2018 年 Chen 等人的标签化 PSI
在有标签的 PSI 中,发送方为其每个项目
剩下的就是构造多项式
4.2 改进措施
上述方法对我们的结构来说并不适用,因为我们把项目分成素字段元素大小的块,并对它们独立计算相交多项式。因此,一个部分匹配,由于素数域的大小很小,可能很容易被破解,会立即泄露标签的相应部分。
幸运的是,[13] 已经为这个问题提供了部分解决方案:由于我们在任何情况下都必须使用
这种方法的一个主要缺点是场操作中插值的
在 [13] 中指出,除了标签结果外,将交集结果返回给接收者严格来说是没有必要的,但在实践中可能需要接收者知道哪些标签值持有有效数据。因此,我们认为标签式 PSI 协议既要返回交集结果,又要返回一个或多个标签结果,这取决于标签是由单个还是多个项目长度的片段组成。
图 2:在这个例子中,有
4.2.1 解决一个微妙的问题
不幸的是,上述方法还有一个技术问题需要解决。为了理解这个问题,请注意,[13] 在大的扩展字段上进行插值,其中一个扩展字段元素编码整个项目。由于项目从不重复,插值总是会成功。由于我们建议对标签的每个基元场大小的部分使用单独的插值多项式,插值是在一个小得多的场上进行的,在这里很容易出现项目部分的碰撞:一个分区(回顾第 3.1.2 节)可能会导致同一仓中出现重复的项目部分。如果相应的标签部分不匹配(很可能是这种情况),内插就不可能进行。
为了解决这个问题,发送者在插入一个项目时,必须检查它的任何部分是否已经出现在该项目被插入的分区的相同位置。如果遇到了碰撞,发送者必须尝试在不同的分区中插入该项目,或者作为最后的手段,创建一个全新的分区,在那里可以插入有问题的项目。
上述程序导致了一个不幸的现象,即与无标签的 PSI 相比,有标签的 PSI 会产生更多的分区,并且对发送方的数据结构的 "填充率" 更低。
4.2.2 安全性
虽然 [13] 没有明确讨论标记情况的安全证明,但我们注意到,理想功能([13],图 3)和非标记情况的安全证明([13],定理 1)可以直接扩展到标记情况。
在理想的功能中,发送方同时输入其集合
5 实验
我们在两个 C++ 库中测试了上述技术,HElib [31] 和 SEAL [57],它们分别实现了 BGV [7] 和 BFV [22] 方案。本节中使用的加密参数至少支持 128 位的安全性,除非另有标注(见表 5 和表 6)。基准测试是在 Intel Xeon Platinum 8272CL CPU @ 2.60 GHz 上进行的,有 24 个物理核心和 192GB 的内存。我们认为这与 [13] 中使用的 32 核机器相当。
两种实现方式的基本原理如下。SEAL 的实现有助于我们与先前的工作 [13, 14] 进行充分的比较。然而,SEAL 支持有限的加密参数集,阻碍了第 3.1 节中的低深度指数化技术 -- 我们降低通信成本的最有力工具。特别是,SEAL 中的环
在基于 SEAL 的实现中,我们旨在展示我们的优化是如何比先前的工作,特别是 [13] 减少运行时间和通信成本的。这种设置利用了第 3.1 节的所有技术,除了低深度指数化方法。在 HElib 的实现中,我们只关注通信成本,并依赖于低深度指数化、SIMD 打包和 Paterson-Stockmeyer 方法。
与 SEAL 版本不同的是,HElib 版本是一个概念验证的实现,写它只是为了演示用于降低通信成本的低深度指数化技术。也就是说,我们没有实现
我们的基于 SEAL 的协议是在一个开源的库中实现的,可在 https://GitHub.com/Microsoft/APSI 中找到。
5.1 基于 SEAL 的实现:无标签模式
表 1 给出了我们在无标签模式下运行的 SEAL 实现的计算和通信成本。对于每一对
表 1 包括与 Chen 等人 [13] 的单线程执行的比较,包括发送方到接收方和接收方到发送方通信的细节。此外,在表 2 中,我们提出了另一个与 Chen 等人 [13]、Kales 等人 [36] 以及 Aranha 和 Resende [54] 的并列比较,这些协议代表了不平衡 PSI 的不同先进协议。
关于 Chen 等人 [13],很明显,我们的协议在很多情况下更快,特别是对于较大的参数,并且在每一种情况下都有更小的通信成本。例如,对于
我们的工作与 Kales 等人 [36] 之间的比较更加细微,因为协议和应用是不同的。对于协议方面,主要的区别是 Kales 等人有一个重要的发送方预处理步骤,并且需要一个可能很大的布谷鸟过滤器
从表中无法看出的是,布谷鸟过滤器也导致 Kales 等人 [36] 有一个不可忽视的假阳性概率。在他们的实验中,他们将布谷鸟过滤器的参数化,使其假阳性概率为
正如 Kales 等人 [36] 和 Chen 等人 [13] 一样,我们也包括与 Aranha 和 Resende [54] 的工作进行比较。然而,我们注意到 [54] 使用了极为激进的布谷鸟过滤器参数,导致在线性能远远优于其他协议,但假阳性率高达
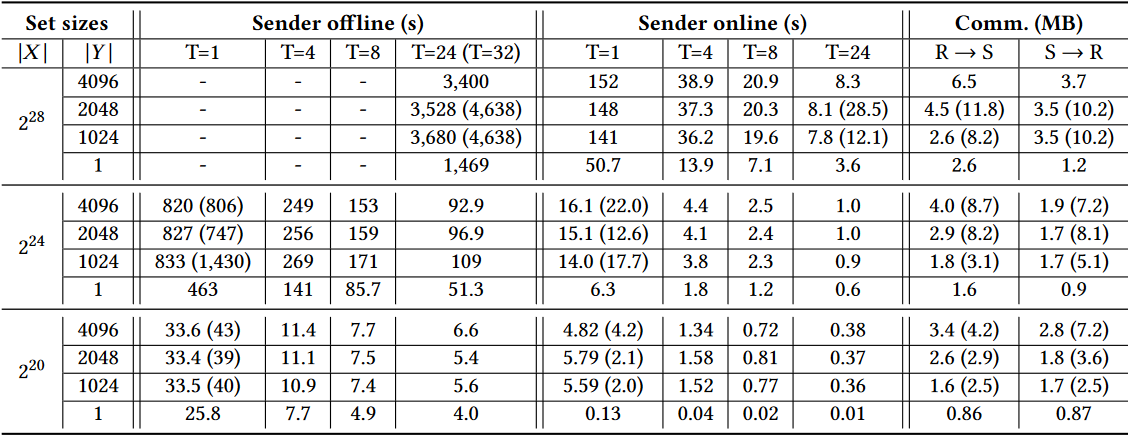
表 1:我们的 SEAL 实现的计算和通信成本。
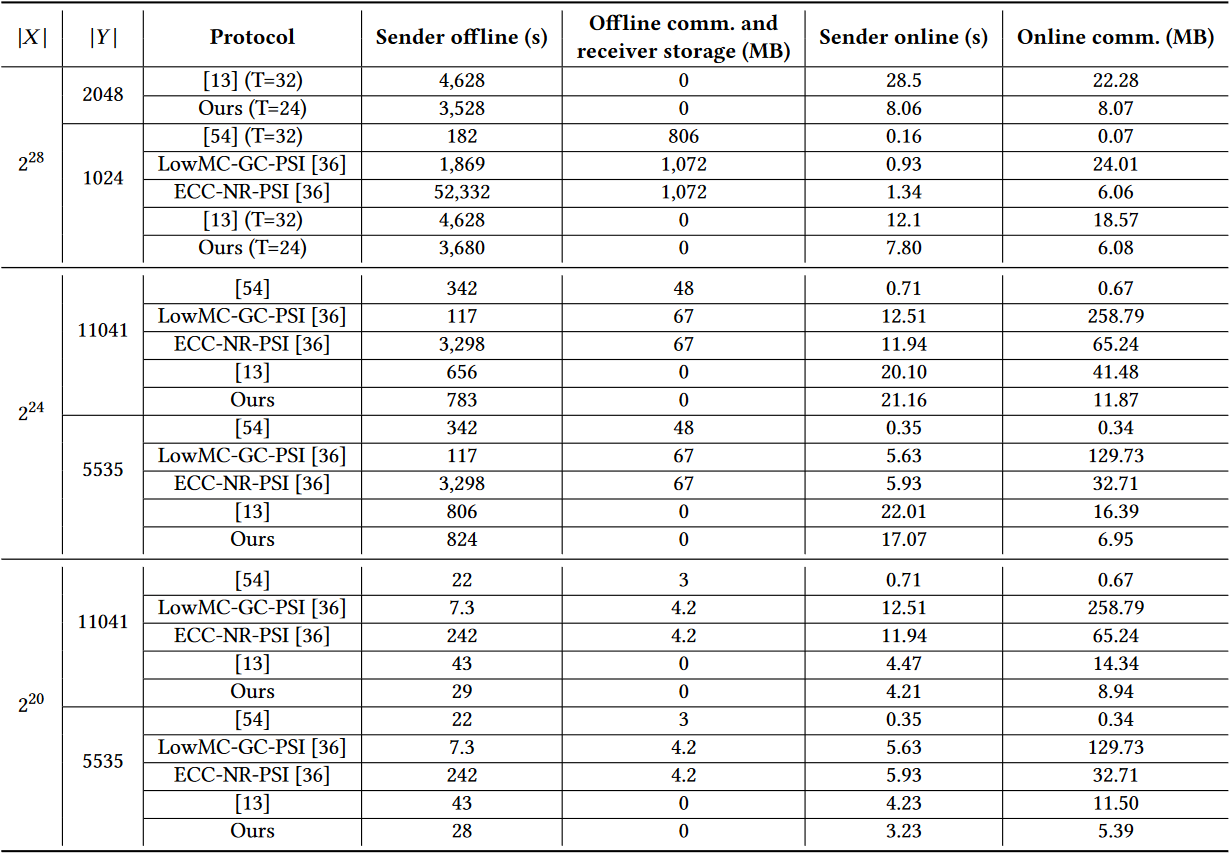
表 2:与先前工作的比较。所有的执行都是单线程的,除了那些线程数被明确标记为
5.2 非常大的发送者
Kales 等人 [36] 指出,在实际应用中,例如移动联系人的发现,遇到超过 10 亿的发送方集合是现实的。虽然我们的协议很容易扩展到这种情况,但在这么大的集合上运行我们的实现需要比我们的系统可用的内存多得多,从而导致大量的分页和在线计算的大量减慢。
因此,对于非常大的发送者来说,更可行的解决方案是将数据集划分为较小的部分,并以较小的参数多次运行该协议。我们注意到,接收方与发送方之间的通信只需要做一次,因此,例如对一个
5.3 基于 SEAL 的实现:标签化模式
我们也在标签模式下演示几个例子。标签的大小很重要,即回顾一下第 4.2 节,如果标签比项目长度(更正确地说,是用来表示项目的
不幸的是,并没有很多有意义的比较点。Chen 等人 [13] 提出了一个与 PIR 论文 [3] 进行比较的单一数据点,其中标签大小为

表 3:在标签字节长度
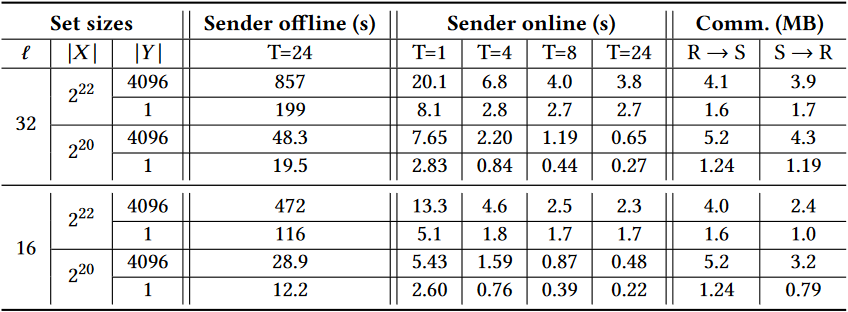
表 4:我们的 SEAL 实现在标签设置中的计算和通信成本。标签的字节大小为
5.4 基于 HElib 的实现:对通信复杂性进行优化
我们在 HElib 中的概念验证实现,旨在说明非平衡 PSI 可以在
如第 3.1.6 节所述,在执行我们的 PSI 协议之前,接收方会向发送方发送
我们的 PSI 协议的通信费用显示在表 6 中。为了比较,我们还包括了 [13] 的通信成本。请注意,在 [13] 中,评估密钥和密码文本是在对称密钥模式下生成的,这使得我们可以将其大小几乎减半。不幸的是,我们无法在 HElib 中使用这种模式,但我们向 [13] 作者索取了公钥模式下的相应通信量。
如表 6 所示,我们的实现的通信成本随着发送方集合的大小增长非常缓慢。例如,对于
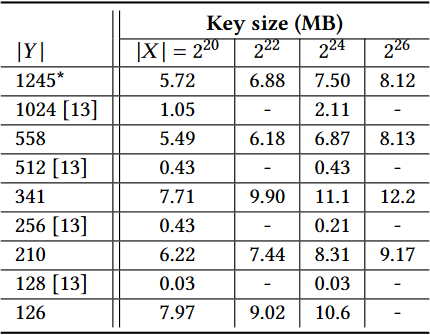
表 5:我们的 HElib 实现和先前工作 [13] 在离线阶段的评估密钥大小。在这些实验中使用的所有参数的安全级别至少是
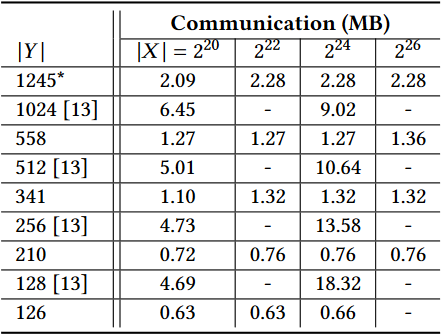
表 6:我们的 HElib 实现和先前工作 [13] 在在线阶段的通信成本。在这些实验中使用的所有参数的安全级别至少是
6 结论
我们已经证明了对 [13] 协议的一些改进,大大降低了通信和在线计算成本。我们的改进实现了非常强大的通信计算权衡,可以利用这些权衡使该协议在各种情况下都是实用的和可扩展的。最后,我们表明,同态加密可以用来在不平衡的情况下实现 PSI,在较大的集合中具有亚对数的通信成本,尽管这个协议现在还不实用。在未来,对同态加密的硬件加速可能会改变这种情况。
鸣谢
我们要感谢 Craig Costello 和 Patrick Longa(微软研究院)在 FourQ 曲线的 hash-tocurve 算法方面提供的重要帮助和建议,以及对 FourQlib 库的支持,还要感谢陈浩(Facebook)在这项工作的初步阶段进行的有益讨论。
这项工作得到了 CyberSecurity Research Flanders 的支持,参考编号为 VR20192203。此外,第一作者得到了美国国防部高级研究计划局(DARPA)和太平洋空间和海军作战系统中心(SSC Pacific)的支持,合同号为 FA8750-19-C-0502。第三位作者得到 ERC 高级拨款 ERC-2015-AdG-IMPaCT 和佛兰德政府通过 FWO SBO 项目 SNIPPET S007619N 的支持。第五位作者得到法兰德斯研究基金会(FWO)的初级博士后研究金的支持。
本材料中表达的任何意见、发现和结论或建议都是作者的观点,不一定反映佛兰德斯网络安全研究中心、DARPA、美国政府、ERC 或 FWO 的观点。美国政府被授权为政府目的而复制和分发重印本,尽管其中有任何版权注释。
最后,我们要感谢匿名审稿人的有益意见。
参考文献
Martin R. Albrecht, Rachel Player, and Sam Scott. 2015. On the concrete hardness of Learning with Errors. J. Mathematical Cryptology 9, 3 (2015), 169203. http://www.degruyter.com/view/j/jmc.2015.9.issue-3/jmc-2015-0016/jmc2015- 0016.xml
Junade Ali. 2018. Validating Leaked Passwords with k-Anonymity. https://blog. cloudflare.com/validating-leaked-passwords-with-k-anonymity/. Accessed: 2021-04-26.
Sebastian Angel, Hao Chen, Kim Laine, and Srinath Setty. 2018. PIR with compressed queries and amortized query processing. In 2018 IEEE Symposium on Security and Privacy (SP). IEEE, 962–979.
Giuseppe Ateniese, Emiliano De Cristofaro, and Gene Tsudik. 2011. (If) Size Matters: Size-Hiding Private Set Intersection. In PKC 2011 (LNCS, Vol. 6571), Dario Catalano, Nelly Fazio, Rosario Gennaro, and Antonio Nicolosi (Eds.). Springer, Heidelberg, 156–173. https://doi.org/10.1007/978-3-642-19379-8_10
Daniel J Bernstein, Mike Hamburg, Anna Krasnova, and Tanja Lange. 2013. Elligator: Elliptic-curve points indistinguishable from uniform random strings. In Proceedings of the 2013 ACM SIGSAC conference on Computer & communications security. 967–980.
Zvika Brakerski. 2012. Fully Homomorphic Encryption without Modulus Switching from Classical GapSVP. In CRYPTO (Lecture Notes in Computer Science, Vol. 7417), Reihaneh Safavi-Naini and Ran Canetti (Eds.). Springer, 868–886.
Zvika Brakerski, Craig Gentry, and Vinod Vaikuntanathan. 2012. (Leveled) fully homomorphic encryption without bootstrapping. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference. ACM, 309–325.
Zvika Brakerski and Vinod Vaikuntanathan. 2011. Fully homomorphic encryption from ring-LWE and security for key dependent messages. In Advances in Cryptology–CRYPTO 2011. Springer, 505–524.
Zvika Brakerski and Vinod Vaikuntanathan. 2014. Efficient fully homomorphic encryption from (standard) LWE. SIAM J. Comput. 43, 2 (2014), 831–871.
Michael F. Challis. 1993. Two new techniques for computing extremal h-bases Ak. Comput. J. 36, 2 (1993), 117–126.
Michael F Challis and John P Robinson. 2010. Some extremal postage stamp bases. Journal of Integer Sequences 13, 2 (2010), 3.
Melissa Chase and Peihan Miao. 2020. Private Set Intersection in the Internet Setting from Lightweight Oblivious PRF. In CRYPTO 2020, Part III (LNCS), Hovav Shacham and Alexandra Boldyreva (Eds.). Springer, Heidelberg, 34–63.
Hao Chen, Zhicong Huang, Kim Laine, and Peter Rindal. 2018. Labeled PSI from Fully Homomorphic Encryption with Malicious Security. In ACM CCS 2018, David Lie, Mohammad Mannan, Michael Backes, and XiaoFeng Wang (Eds.). ACM Press, 1223–1237. https://doi.org/10.1145/3243734.3243836
Hao Chen, Kim Laine, and Peter Rindal. 2017. Fast Private Set Intersection from Homomorphic Encryption. In ACM CCS 2017, Bhavani M. Thuraisingham, David Evans, Tal Malkin, and Dongyan Xu (Eds.). ACM Press, 1243–1255. https://doi.org/10.1145/3133956.3134061
Ilaria Chillotti, Nicolas Gama, Mariya Georgieva, and Malika Izabachene. 2016. Faster fully homomorphic encryption: Bootstrapping in less than 0.1 seconds. In International Conference on the Theory and Application of Cryptology and Information Security. Springer, 3–33.
Benny Chor, Niv Gilboa, and Moni Naor. 1997. Private information retrieval by keywords. Citeseer.
Craig Costello and Patrick Longa. 2015. FourQ: four-dimensional decompositions on a Q-curve over the Mersenne prime. Cryptology ePrint Archive, Report 2015/565. https://eprint.iacr.org/2015/565.
Whitfield Diffie and Martin E. Hellman. 1976. New Directions in Cryptography. IEEE Transactions on Information Theory 22, 6 (1976), 644–654.
Changyu Dong, Liqun Chen, and Zikai Wen. 2013. When private set intersection meets big data: an efficient and scalable protocol. In ACM CCS 2013, Ahmad-Reza Sadeghi, Virgil D. Gligor, and Moti Yung (Eds.). ACM Press, 789–800. https: //doi.org/10.1145/2508859.2516701
Léo Ducas and Daniele Micciancio. 2015. FHEW: Bootstrapping Homomorphic Encryption in Less Than a Second. In EUROCRYPT 2015, Part I (LNCS, Vol. 9056), Elisabeth Oswald and Marc Fischlin (Eds.). Springer, Heidelberg, 617–640.
Bin Fan, Dave G. Andersen, Michael Kaminsky, and Michael D. Mitzenmacher. 2014. Cuckoo Filter: Practically Better Than Bloom. In Proceedings of the 10th ACM International on Conference on Emerging Networking Experiments and Technologies (Sydney, Australia) (CoNEXT ’14). Association for Computing Machinery, New York, NY, USA, 75–88. https://doi.org/10.1145/2674005.2674994
Junfeng Fan and Frederik Vercauteren. 2012. Somewhat Practical Fully Homomorphic Encryption. Cryptology ePrint Archive, Report 2012/144. http: //eprint.iacr.org/.
Michael J. Freedman, Yuval Ishai, Benny Pinkas, and Omer Reingold. 2005. Keyword Search and Oblivious Pseudorandom Functions. In TCC 2005 (LNCS, Vol. 3378), Joe Kilian (Ed.). Springer, Heidelberg, 303–324.
Michael J. Freedman, Kobbi Nissim, and Benny Pinkas. 2004. Efficient Private Matching and Set Intersection. In EUROCRYPT 2004 (LNCS, Vol. 3027), Christian Cachin and Jan Camenisch (Eds.). Springer, Heidelberg, 1–19. https://doi.org/10. 1007/978- 3- 540- 24676- 3_1
Craig Gentry. 2009. Fully homomorphic encryption using ideal lattices.. In STOC, Vol. 9. 169–178.
Craig Gentry, Shai Halevi, and Nigel P Smart. 2012. Homomorphic evaluation of the AES circuit. In Advances in Cryptology–CRYPTO 2012. Springer, 850–867.
Craig Gentry, Amit Sahai, and Brent Waters. 2013. Homomorphic Encryption from Learning with Errors: Conceptually-Simpler, Asymptotically-Faster, Attribute-Based. In CRYPTO (1) (Lecture Notes in Computer Science, Vol. 8042), Ran Canetti and Juan A. Garay (Eds.). Springer, 75–92. https://doi.org/10.1007/9783- 642- 40041- 4
Christoph Hagen, Christian Weinert, Christoph Sendner, Alexandra Dmitrienko, and Thomas Schneider. 2021. All the Numbers are US: Large-scale Abuse of Contact Discovery in Mobile Messengers. In 28th Annual Network and Distributed System Security Symposium, NDSS. The Internet Society.
Shai Halevi and Victor Shoup. 2020. Design and implementation of HElib: a homomorphic encryption library. Cryptology ePrint Archive, Report 2020/1481. https://eprint.iacr.org/2020/1481.
Carmit Hazay and Yehuda Lindell. 2008. Efficient Protocols for Set Intersection and Pattern Matching with Security Against Malicious and Covert Adversaries. In Theory of Cryptography, Ran Canetti (Ed.). Springer Berlin Heidelberg, Berlin, Heidelberg, 155–175.
HElib 2021. HElib: An Implementation of homomorphic encryption (2.1.0). https://github.com/homenc/HElib. IBM.
Yan Huang, David Evans, and Jonathan Katz. 2012. Private Set Intersection: Are Garbled Circuits Better than Custom Protocols?. In NDSS 2012. The Internet Society.
Bernardo A. Huberman, Matt Franklin, and Tad Hogg. 1999. Enhancing Privacy and Trust in Electronic Communities. In Proceedings of the 1st ACM Conference on Electronic Commerce (Denver, Colorado, USA) (EC ’99). Association for Computing Machinery, New York, NY, USA, 78–86. https://doi.org/10.1145/336992.337012
Yuval Ishai, Joe Kilian, Kobbi Nissim, and Erez Petrank. 2003. Extending Oblivious Transfers Efficiently. In CRYPTO 2003 (LNCS, Vol. 2729), Dan Boneh (Ed.). Springer, Heidelberg, 145–161. https://doi.org/10.1007/978-3-540-45146-4_9
Stanisław Jarecki and Xiaomin Liu. 2010. Fast secure computation of set intersection. In International Conference on Security and Cryptography for Networks. Springer, 418–435.
Daniel Kales, Christian Rechberger, Thomas Schneider, Matthias Senker, and Christian Weinert. 2019. Mobile Private Contact Discovery at Scale. In USENIX Security 2019, Nadia Heninger and Patrick Traynor (Eds.). USENIX Association, 1447–1464.
Sreekanth Kannepalli, Kim Laine, and Radames Cruz Moreno. 2021. Password Monitor: Safeguarding passwords in Microsoft Edge. https: //www.microsoft.com/en- us/research/blog/password- monitor- safeguardingpasswords-in-microsoft-edge/. Accessed: 2021-04-26.
Andrey Kim, Yuriy Polyakov, and Vincent Zucca. 2021. Revisiting Homomorphic Encryption Schemes for Finite Fields. Cryptology ePrint Archive, Report 2021/204. https://eprint.iacr.org/2021/204.
Ágnes Kiss, Jian Liu, Thomas Schneider, N. Asokan, and Benny Pinkas. 2017. Private Set Intersection for Unequal Set Sizes with Mobile Applications. PoPETs 2017, 4 (Oct. 2017), 177–197. https://doi.org/10.1515/popets-2017-0044
Vladimir Kolesnikov, Ranjit Kumaresan, Mike Rosulek, and Ni Trieu. 2016. Efficient Batched Oblivious PRF with Applications to Private Set Intersection. In ACM CCS 2016, Edgar R. Weippl, Stefan Katzenbeisser, Christopher Kruegel, Andrew C. Myers, and Shai Halevi (Eds.). ACM Press, 818–829. https://doi.org/ 10.1145/2976749.2978381
Vadim Lyubashevsky, Chris Peikert, and Oded Regev. 2013. On ideal lattices and learning with errors over rings. Journal of the ACM (JACM) 60, 6 (2013), 43.
Moxie Marlinspike. 2014. The Difficulty Of Private Contact Discovery. A company sponsored blog post. https://signal.org/blog/contact-discovery/.
C. Meadows. 1986. A More Efficient Cryptographic Matchmaking Protocol for Use in the Absence of a Continuously Available Third Party. In 1986 IEEE Symposium on Security and Privacy. 134–134. https://doi.org/10.1109/SP.1986.10022
Moni Naor and Omer Reingold. 2004. Number-theoretic constructions of efficient pseudo-random functions. Journal of the ACM 51, 2 (2004), 231–262.
Andrew Odlyzko. 2003. Privacy, economics, and price discrimination on the Internet. In Proceedings of the 5th international conference on Electronic commerce. ACM, 355–366.
Michele Orrù, Emmanuela Orsini, and Peter Scholl. 2017. Actively Secure 1-outof-N OT Extension with Application to Private Set Intersection. In CT-RSA 2017 (LNCS, Vol. 10159), Helena Handschuh (Ed.). Springer, Heidelberg, 381–396. https: //doi.org/10.1007/978- 3- 319- 52153- 4_22
Michael S Paterson and Larry J Stockmeyer. 1973. On the number of nonscalar multiplications necessary to evaluate polynomials. SIAM J. Comput. 2, 1 (1973), 60–66.
Benny Pinkas, Mike Rosulek, Ni Trieu, and Avishay Yanai. 2020. PSI from PaXoS: Fast, Malicious Private Set Intersection. In EUROCRYPT 2020, Part II (LNCS), Vincent Rijmen and Yuval Ishai (Eds.). Springer, Heidelberg, 739–767.
Benny Pinkas, Thomas Schneider, Gil Segev, and Michael Zohner. 2015. Phasing: Private set intersection using permutation-based hashing. In 24th USENIX Security Symposium (USENIX Security 15). 515–530.
Benny Pinkas, Thomas Schneider, Nigel P. Smart, and Stephen C. Williams. 2009. Secure Two-Party Computation Is Practical. In ASIACRYPT 2009 (LNCS, Vol. 5912), Mitsuru Matsui (Ed.). Springer, Heidelberg, 250–267.
Benny Pinkas, Thomas Schneider, Christian Weinert, and Udi Wieder. 2018. Efficient Circuit-Based PSI via Cuckoo Hashing. In EUROCRYPT 2018, Part III (LNCS, Vol. 10822), Jesper Buus Nielsen and Vincent Rijmen (Eds.). Springer, Heidelberg, 125–157. https://doi.org/10.1007/978-3-319-78372-7_5
Benny Pinkas, Thomas Schneider, and Michael Zohner. 2014. Faster Private Set Intersection Based on OT Extension. In USENIX Security 2014, Kevin Fu and Jaeyeon Jung (Eds.). USENIX Association, 797–812.
Oded Regev. 2005. On lattices, learning with errors, random linear codes, and cryptography. In Proceedings of the 37th Annual ACM Symposium on Theory of Computing, Baltimore, MD, USA, May 22-24, 2005, Harold N. Gabow and Ronald Fagin (Eds.). ACM, 84–93. https://doi.org/10.1145/1060590.1060603
Amanda C. Davi Resende and Diego F. Aranha. 2018. Faster Unbalanced Private Set Intersection. In FC 2018 (LNCS, Vol. 10957), Sarah Meiklejohn and Kazue Sako (Eds.). Springer, Heidelberg, 203–221.
Peter Rindal and Mike Rosulek. 2017. Malicious-Secure Private Set Intersection via Dual Execution. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (Dallas, Texas, USA) (CCS ’17). ACM, New York, NY, USA, 1229–1242. https://doi.org/10.1145/3133956.3134044
Michael Scott. 2020. A note on the calculation of some functions in finite fields: Tricks of the Trade. Cryptology ePrint Archive, Report 2020/1497. https: //eprint.iacr.org/2020/1497.
SEAL 2020. Microsoft SEAL (release 3.6). https://github.com/Microsoft/SEAL. Microsoft Research, Redmond, WA..
Victor Shoup. 2021. NTL: A Library for doing Number Theory (11.4.3). https: //libntl.org/.
Nigel P Smart and Frederik Vercauteren. 2014. Fully homomorphic SIMD operations. Designs, codes and cryptography 71, 1 (2014), 57–81.
Ni Trieu, Kareem Shehata, Prateek Saxena, Reza Shokri, and Dawn Song. 2020. Epione: Lightweight contact tracing with strong privacy.
Andrew Chi-Chih Yao. 1986. How to Generate and Exchange Secrets (Extended Abstract). In 27th FOCS. IEEE Computer Society Press, 162–167. https://doi.org/ 10.1109/SFCS.1986.25